
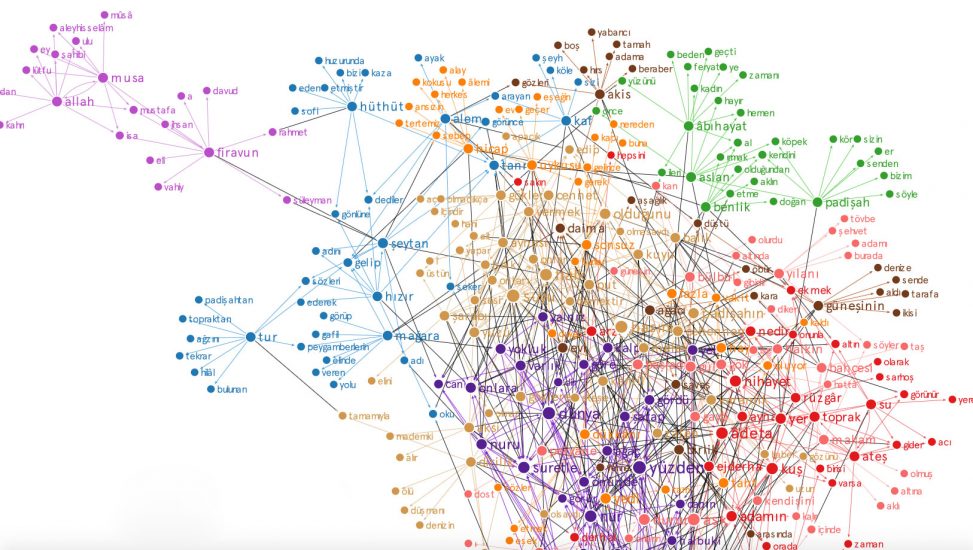
I started a symbol map research applying computational methods on the text of the Mesnevi by Hz. Mevlana Jalāl ad-Dīn Rūmī.
My goal was to discover connections as archetypal symbols. When I analyzed a big map of all symbols and clusters took place, Bridge symbols emerged that also linked symbol sets. Perhaps we can call it symbols of symbols. Or perhaps the main pillars of Mesnevi. I wanted to share the preliminary results with you.
These bridge symbols are: Sky/Gökyüzü, Earth/Yeryüzü, Hz. Solomon/Hz. Süleyman, Sea/Deniz War/Savaş, Moon/Kamer, Kaf Mountain, Face/Yüz, Entity/Varlık, God/Tanrı, Garden/Bahçe
Research steps:
- 6 volume of Mesnevi raw text is collected
- Raw text preprocessed for cleaning unnecessary letters , punctuations, numbers and stop-words
- Deep learning based lemmatization algorithm applied
- Cosine similarity on word embedding applied to the final version of the text
- Predetermined a list of symbolic words initiated the network first. Total 129 words determined for the initiation of the network. Those words are selected according to the Jungian Archetypal Psychology perspective. Those are the ones mostly repetead in mythic motifs, dreams and world myths where they belong to the collective unconscious.
- Top 10 most similar words predicted for each symbol in the list using the trained word embedding model. And eventually all connected in a network.
- A new connected network file is created for the visualization phase
- Social network analysis methods applied to the connected symbol space :
- Betweenness centrality and degree centrality results analyzed
- Betweenness centrality analysis revealed some hub-like behaving symbols in the raw text .
- Those are: Gökyüzü, Yeryüzü, Hz. Süleyman, Deniz, Savaş, Kamer, Kaf, Yüz, Varlık, Tanrı , Bahçe

Lemmatization algorithm
This lemmatization algorithm uses a supervised deep learning approach running on Keras. To optimize the training ability of the lemmatizer model, first I have developed a new lemmatization logic with a certain set of lexical decisions given according to the different lexical families of Turkish words and their meaning. I needed to keep the semantic properties of the words. With this special logic, a new set of training data (with more than 10.000 labeled lemmatization samples) has been set up(10% splitted as test data). A sequence to sequence model by the use of “Long Short Term Memory” is trained with this special data set in Keras. 200 epoch running of this model achieved the best possible lemmatized-root which still can keep the semantical meaning to be able to use in the word-embedding step which runs next.